
Neuromorphic Computing: A New Era of Computing is Here
Serial Computing to Parallel Computing to Neuromorphic Computing to Quantum?

For the software industry, the ability to compute at scale is key. It’s why cloud computing became so important. Instead of heavy manual provisioning of servers, you can autoscale up and down while only paying for what you use.
Behind all of that are the CPUs and GPUs that power what we collectively experience as software and features. CPUs that handle requests. GPUs that perform modeling for features. It’s all great but there are limits to the scale, capability, and availability of computing. Hell, there are some Nvidia GPUs that have a “black market” price that rivals crack cocaine at this point. They’re that damn valuable as we emerge into the next generation of AI.
Like all technology trends since the dawn of time, resource constraints generate an incredible breeding ground for innovation. The scarcity of resources ends up becoming one of the greatest weapons and drivers of innovation.
In this essay of Beyond the Yellow Woods, we’re going to go out to the edge of where computing is going next. I have a deep passion for this topic as hardware is where I got my start in the technology space. Strap in folks, it’s time to take the less beaten path!
The Recent History of Processors
We all love history, right? No? Ok well too bad, because we need to start with some history before we move on!
Our journey starts during the 1940s-1950s during the WWII era. A brainchild of the US government during wartime efforts, ENIAC can be considered a starting point in our journey of processors. ENIAC stands for Electronic Numerical Integrator and Computer. Vacuum tubes were how it processed information. In essence, we’d heat the cathode up which emits electrons (thermionic emission) and we’d control the flow of these electrons by changing the voltage applied. At the end of the process is an Anode which would collect the electrons flowing through the cathode, creating an electrical circuit. ENIAC used roughly 17,500 vacuum tubes, creating a “circuit” of logic that electrical currents would move through. The challenge here is that these tubes would overheat and fail, requiring the researchers to swap dozens out multiple times a day. So, conceptually cool but practicality for scale? Not so much.

In the late 1940s, the famous Bell Labs invented the transistor. From an architectural perspective, the semiconductor was built on a piece of germanium with what they called “Point-Contact Design”. In summary, the design of this was a thin strip of germanium with two closely spaced gold contacts (called “points”) which made up the transistor.
The point-contact transistor could amplify electrical signals and by modulating the pressure on the germanium crystal, you could alter the current flowing between the contacts. Thus, you can amplify or switch signals flowing through the transistor.
Huzzah! We’ve turned sand into basic logic. And now, our journey really starts.
Skipping over some key years and development, we’re now up to 1971 when Intel released their Intel 4004 microprocessor. This was the first commercially available (and viable) processor to hit the market.

From a technical perspective, the 4004 was a 4-bit processor and could process chunks of 4-bit data at a “clock speed'“ of 740 kHz. Simply put, clock speed is just how frequently a processor can create electrical pulses to flow through the transistors. The 4004 had 2,300 transistors and had a 45-instruction set (a group of commands).
Given that this was the first commercially available and affordable processor (CPU), it set off a frenzy of demand, creating a new growth curve for the industry. Intel dominated the industry with few competitors making a dent, such as IBM and AMD through the 2000’s.
From the 1990’s to 2000’s, we started to see the evolution of CPUs in the form of multicore/threaded CPUs as well as the early stage of parallel computing. This was driven by single-core CPU performance hitting a plateau. This took the same principle architecture, shrunk it, and put multiple of them on the same CPU.
I’m glossing over some details but this paints the broad strokes of how we got to where we’re at today. Throughout all of this, we’ve had a hidden trend of machine learning and artificial intelligence development since the 1970s with folks talking about neural networks well before it was a “thing”. This started to take off in the early 2010s as we discovered that Graphics Processing Units (GPUs) have a unique architecture well suited for the space. Let’s dive into that for a second.
The Dark Horse That Now Dominates
In 1993 a brilliant individual created what felt like a small, niche company at the time called Nvidia. Jensen Huang, a Taiwanese-American electrical engineer, founded Nvidia to bring a new evolution of graphics processing to the space. What most view as an overnight success was actually an incredibly long slog and game of survival in order to become one of the most valuable companies in the world.
Nvidia was created right when the video game era started to take off. Video games require a substantial amount of compute power - often in parallel ways - that traditional Intel and AMD CPUs were not best suited to handle. Originally, they could in a limited way but as game developers and video game engines started to push the limits, there was an emerging market need for offloading the complex computations onto a separate device (known as accelerated computing).
Nvidia wasn’t initially a deep success. Their first GPUs, named the NV1 and NV2, didn’t sell well in the market due to their value-to-cost not being sufficient for computer manufacturers or enthusiasts to consider them. Then, the company’s 3rd product, the RIVA 128, became a smashing success, selling millions of units in just a few months. In what is now an infamous saying that is engrained into the pace and culture of Nvidia, Jensen Huang held an all-hands with the company to let them know “Our company is thirty days from going out of business”. RIVA 128 was launched in August of 1997. At the launch date, the company had just enough cash left to fund payroll for the next 30 days.

Before I dive into the architecture, I just want to sit on that point for a second. Nvidia essentially launched the evolution of video games, ML, and AI that we know today. The world would be a fundamentally different place and it all hinged on just a 30-day window to make payroll. Sometimes, the best companies are formed in the most dire of times.
The RIVA 128 GPU had three distinct architectural qualities that bent the arch of accelerated computing at that time:
Direct3D and OpenGL Support: The RIVA 128 focused on accelerating Direct3D, aligning with the Direct3D 5 and OpenGL API specifications, an area where the NV1 and NV2 failed. This was very important as the gaming industry started to move heavily into 3D graphics.
Transistors Density and Fabrication Scale: RIVA 128 was built with 3.5 million transistors using at 350 nm fabrication scale, clocking in at 100 MHz (the leader at the time).
Rendering Capabilities: RIVA 128 featured a single-pixel pipeline that could process one pixel per clock cycle, and could output 100 million pixels and 1.5 million 25-pixel triangles per second. It also had on-chip memory for caching pixels and vertexes for faster real-time performance.
It was the RIVA 128 that made the major leap for Nvidia into the accelerated computing space. That momentum carried them through the 2000s as the gaming revolution kicked off. However, throughout that journey, Huang and his team discovered an adjacent use case unique to GPUs: High-Performance Computing (HPC).
In 2007, Nvidia started to shift into the HPC market with the launch of their Telsa GPUs which were based on their G80 architecture that was built for their GeForce 8800 GPUs. The launch of their Tesla line marked the demarcation line in how we utilized GPUs and what for. More importantly, it started the leap into the movement from Serial to Parallel computing.

Serial to Parallel Computing
In 2004, I was lucky enough to get a basic Dell PC for Christmas. 8 hours after getting it running, I started to get blue screens of death (BSODs) due to faulty RAM. Obviously, as a 13-year-old at the time, I was pissed because I just wanted to play video games. I complained to my Dad who said “Figure it out” to which I sat on the phone with India tech support for hours and hours before finally getting a replacement.
I had dabbled in basic computer modifications prior to this but this event sent me into a frenzy. It was at that time that I became convinced I could build a better PC than Dell for a relatively similar price point. So, I did just that. I took the money I had gotten from working summer jobs doing sprinkler and landscaping work and bought all of the components for my new computer. I had to teach myself how all components work but, fortunately, computers are a lot like building legos which really isn’t all that complex on the surface.
This time, I purchased an Nvidia GPU for my build which netted me the best gaming computer among my friends. Plus, it had a clear side case with neon blue lights so you could see the epicness inside. Oh, the joys of being 13 again.
By the time I turned 14, I had built many gaming computers for my friends. I decided to build a company on it so I could make money and incorporated a company called Rage Computers Inc. It wasn’t explosive growth but I made decent money, charging a flat-rate profit of $200/computer. To help fuel the demand in my local city (we didn’t have a website), I started to host Counter Strike tournaments in my Dad’s basement. This forced me to get into building servers and understanding networking.

Our setup was honestly epic. We used 2 separate bedrooms that housed 5 computers each, which represented the two different teams. In the living room, we had a giant 50” plasma TV that broadcast the “god view” of the map and had dozens of couches and chairs for spectators. The servers were required to host the game locally and we used a giant 100 Mbps 40 port switch to link all of the gamers together. What started as a small project with only a handful of folks joining turned into large LAN tournaments where teams would assemble, buy into the tournament, and compete to win. Our largest tournament pool was just over $3k.
My movement into servers prompted my Dad to take action and help me grow. He was an HPC admin at Colorado State University at the time and was tasked with moving and sourcing clusters for different HPC applications. He contracted my company to help give us revenue, providing me with an incredible opportunity to learn. Coincidentally, at the same time, my dad was working on protein folding prediction as a consulting project. One of its unique academic angles was visualizing the predicted protein structure, which was extremely computationally intensive as it fully relied on CPUs. My Dad, being the nerdy guy he is, expanded the application to take advantage of OpenGL which meant that we could leverage the Nvidia GPUs and essentially “parallel process” the pixel rendering. This was in 2006 - bleeding edge at the time.
This changed everything for my company. I started to demonstrate the ability of these computers to render complex visualizations for industries like bioinformatics, computational fluid dynamics, and theoretical mathematics. The sales demo was simple: load up the applications using CPU only and load it up using GPUs. The speed and difference were mind-bending. This ended up landing me a few higher-profile sales of my HPC desktops as well as some smaller cluster builds (<40 blades).
I ended up selling & liquidating the company late in 2006 (my biggest life regret that I’ll do a separate essay on) just as cloud computing was becoming a thing and just before Nvidia released the Tesla line that boasted architecture specifically for the field of work I was playing in. It’s worth noting that I was prototyping Xen Hypervisor for remote desktop access for a client I had in Denver. Being 15 at the time, any time the machine had an issue, my Dad would have to drive me to Denver to fix it onsite since I didn’t have my license. He finally said “Figure out a different way” so I started to test virtualizing the entire computer through Xen and a cluster that was local to our hometown. This was the same time that AWS was emerging… shoulda, coulda, woulda.
I tell this backstory simply to give a bit of perspective from being in the trenches during that timeframe and what it felt like, especially since we straddled the line of gaming computers, professional computers, and the emerging cloud computing trend. The change was happening so fast that it was difficult to keep up on all of the vectors of emerging technology at the time.
In 2007, the Compute Unified Device Architecture (CUDA) language paired with the Nvidia Tesla GPUs were both launched, providing a full hardware/software stack for the HPC market - something truly revolutionary at the time. While it didn’t take off initially, this launch ended up becoming yet another demarcation line in the pace of innovation. Used initially for the use cases I described, it quickly became apparent over the subsequent years that this stack was way more efficient than using general CPUs and it opened up an entirely new way for engineers to think about what we could achieve with software.
Starting in the mid to late 2000s, there emerged a wave of ML/AI engineers using GPUs to train models in a cost-efficient way. The key difference came down to the parallel architecture of the processors being more efficient for mathematical processing than CPUs.
At its core, serial and parallel computing represent two fundamental approaches to processing data and executing computations, each with its unique architectural characteristics.
In serial computing, we have sequential execution of instructions that are executed one after another. To get to the next step, we must complete the first. This is processed by one CPU at a time, often done on multiple threads of the CPU. We can get some parallelism with multithreaded CPUs but they don’t have the same amount of cores as GPUs given their intended use case difference.
The limitations are obvious here: you are limited substantially by the clock speed of the processor and, given the serial nature, complex computation tasks that can be done in parallel are incredibly inefficient when compared to GPUs. This isn’t to say that CPUs are worthless, just that as our world relies on more complex computations, they become less valuable.
On the other hand, parallel computing allows for the execution of multiple instructions at the same time by dividing the problem set into smaller, independent tasks that can be computed concurrently. This is achieved through the physical architecture of GPUs by separating the computations into the thousands of “cores” that a GPU has. GPUs were originally designed to handle the processing of large blocks of data in parallel, specifically pixels, where the computation involves running through the same operation of many data points rendered on the screen at the same time. This is known as Single Instruction, Multiple Data (SIMD).
Another key difference between CPUs and GPUs is that CPUs have limited memory bandwidth for processing data and don’t have enough space locally to store data in memory. They have to go out to the computer RAM, limiting the bandwidth to roughly 25-50 GB/s. On the other hand, GPUs have memory on board (called VRAM) which is designed for extremely high memory bandwidth due to the amount of data it has to render on a screen (pixels) at any given point in time. We typically see 200 - 1,000 GB/s, giving the user the ability to move a shit load more data than a CPU while also breaking down the problem set to be done in parallel.
The drawbacks for GPUs are that we have to fundamentally think differently about the problems and algorithms because we’re chunking the problem up. Additionally, you have a lot of other challenges like synchronization, data splitting, merging the results as they come in from the different tasks, etc. It’s important to note too that not all tasks or problems are well suited for parallelization.

In the timeline of processors, we went from serial computing with CPUs to parallel computing with GPUs. They’re both still in use with GPUs becoming one of the hottest commodities to have, especially in the emerging age of generative AI/large language models.
From my vantage point, I always thought that the next evolution would be quantum computing, purely from looking at the exponential growth of processing. However, I believe I was wrong as a new competitor emerges that is making larger strides in viability when compared to quantum computers: Neuromorphic processors and computing.
Parallel Computing to Quantum or Neuromorphic: A New Battle Landscape
There are interesting limitations all over the place as we start to climb the ladder of complexity of computations that we need computers to perform for us. What we originally thought was “complex” in 2007 is now table stakes.
A really simple example of this is physics-based calculations. When I was creating high-end gaming computers, one of the things that made us stand out was that we included a GPU that specifically handled the physics calculations in video games. A company called Ageia had a GPU called PhysX that sat in either the PCIe 1x or 16x slot, designed to handle the video game physics calculations based on the PhysX DSK (formerly known as NovodeX SDK).

I still vividly remember when we first demoed this at a local conference and played a demo map on Unreal Tournament 3. While the video is low resolution, the thing to note here is the unique destruction properties and physics nature of them. Remember, this was bleeding edge at the time and we’d never really seen anything quite like it. Another good example where you can really see the difference is in this demo video. When we showed these off, it blew people’s minds.
Nvidia ended up buying Ageia in 2008 and merging its architecture and SDK into the broader Nvidia portfolio. Even today, we continue to see this consolidation within the hardware space as we push the limits of what we can do with computers.
Throughout this timeline, my impression had always been that we were going to see a significant decline in serial processors (CPUs) and a substantial increase in parallel processing (GPUs) which has largely been correct. From there, my bet had always been on quantum computers simply because it was the next logarithmic step to make in terms of computational complexity.
Before we dive into my false assumptions, it’s worth briefly diving into what a quantum computer is. If you haven’t read my other essay on “Why these physics principles and not others?”, I’d recommend doing so if you want to go deeper into some of the magic I’m about to describe.
Quantum computers largely take advantage of a quantum principle called “superposition”. Where classical computers allow us to define a bit as a 0 or 1, quantum superposition allows us to define a bit as a 0, 1, or both at the same time. This means we can theoretically calculate a substantial amount of possibilities or scenarios at the same time.
On top of that, quantum computers can take advantage of quantum entanglement. In the quantum computing world, classical “bits” are called “qubits”. With quantum entanglement, we can string together a bunch of qubits into an entangled state where one qubit is directly related to another - regardless of the distance - with immediate impact. Literally zero latency. No time is wasted in moving electrons around, which means we can process an incredible amount of information extremely fast.
Lastly, quantum computers also have a concept called “interference" which is the real lynchpin (in my opinion) that sets quantum computing apart from the rest. Quantum interference arises from the wave-like nature of particles at the quantum level. Just like waves in water, qubits can interfere with each other constructively or destructively. Breaking that down:
Constructive Interference: When the peaks of two waves align, they add up, leading to constructive interference. This amplifies the probability amplitude (a measure related to the likelihood of finding a particle in a particular state).
Destructive Interference: Conversely, when the peak of one wave aligns with the trough of another, they cancel each other out, resulting in destructive interference. This reduces the probability amplitude.
In practical terms, this means that quantum computers are extraordinarily effective at finding solutions to problems that are in highly uncertain states. In a quantum algorithm, interference is used to combine the complex probability amplitudes of different paths that the qubits go through due to superposition. We can design quantum circuits/gates and algorithms to ensure that the paths leading to correct answers undergo constructive interference, while incorrect paths undergo destructive interference.
Putting this into a real use case, let’s take the example of searching a database. There’s an algorithm called Grover's algorithm which provides a quadratic speedup for searching unsorted and unstructured data in a database. Traditional search algorithms require O(N) operations to find a solution in a list of N items, but Grover's algorithm can find the solution in approximately O(√N) operations. The algorithm works by repeatedly applying two main steps: the Grover operator, which inverts the amplitude of the target item, and a diffusion operator, which inverts the amplitude of all items about their average. These steps amplify the probability of the correct item being observed when the quantum state is measured.
Interference is key here to significantly reducing the number of steps needed to find the correct item. The algorithm amplifies the amplitude of the correct answer while suppressing the others, allowing it to be found with a much higher probability in a single measurement.
Going further into use cases, quantum computing is great for:
Solving problems where there is a probabilistic nature instead of a deterministic nature.
Calculating multiple probabilities at the same time, essentially finding solutions to a problem where the potential outcome or solution space is huge.
Solving problems where inferencing across unsorted or unstructured data within large data sets.

This all sounds like a perfect panacea for us humans so there’s got to be a “gotcha” in all of this… and there is.
Quantum computers have many headwinds that limit the progress we can make on them. The number one challenge we have is maintaining a quantum coherent state. It’s super difficult to do because quantum states are extremely sensitive to environmental interference, such as temperature changes, vibrations, or electromagnetic radiation. The moment there’s outside interference is the moment that the entire system collapses from a quantum to a classical state, making managing these systems extremely precarious.
Apart from that, we’re still finding and exploring the use cases for these types of systems. Much of this comes down to special algorithm development, error handling and tolerance, and scalability. We’re making progress on all fronts but it is relatively incremental and slow when compared to other computing progress we’re making - such as neuromorphic computing.
And this, my friends, is where I think we will see the next major innovation battleground in the semiconductor industry. Part of what is driving this innovation is that we’re getting less yield the smaller we go on the traditional semiconductor wafer side (nanometers). The cost of standing up these plants is extraordinary, the fabrication process is super difficult, and the performance is starting to plateau. This post does a great job of explaining what is happening, but the following charts stand out to me.
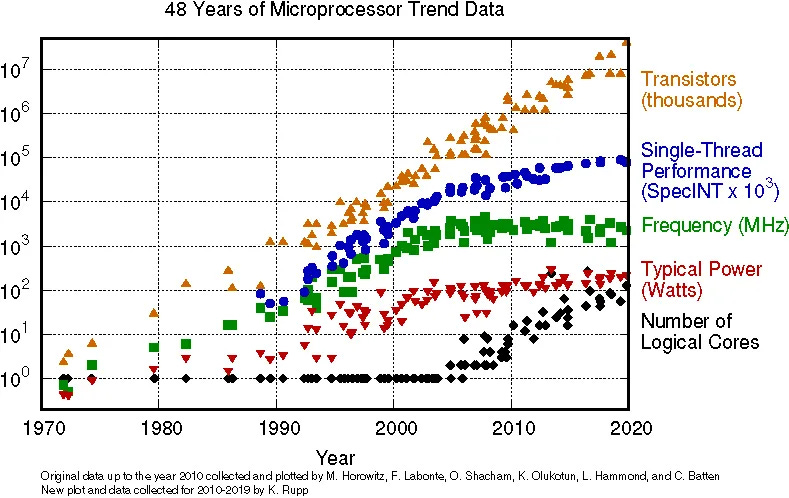
While the transistor count is up, everything else is plateauing (except the number of logical cores). At the same time, our ability to go down into the 2nm range relative to cost has plateaued. Meaning, that the cost stays the same regardless of how small we go.
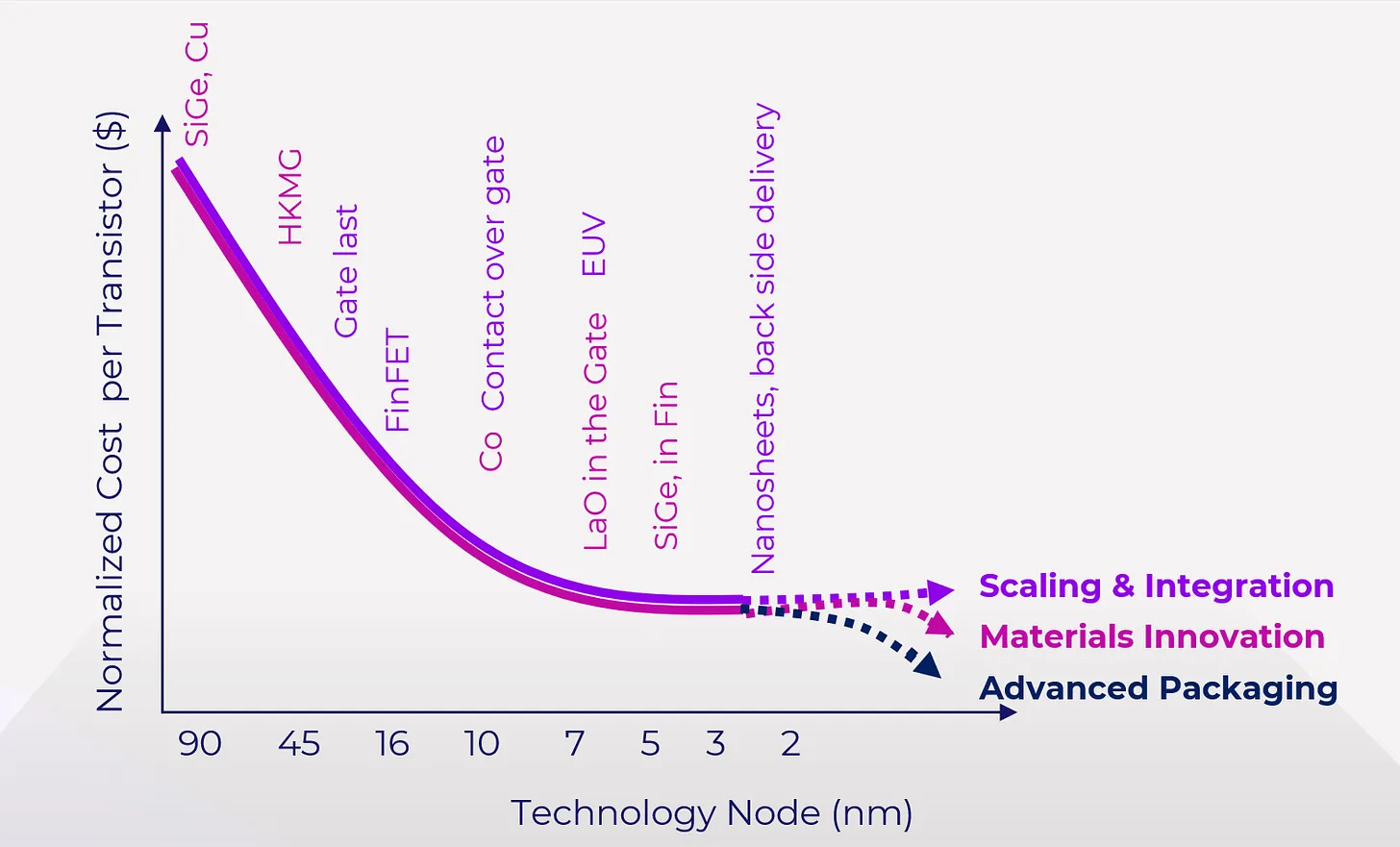
What this means, from my perspective, is that we’re on the brink of an innovative breakthrough within the private markets to keep at or above Moore’s law.
I used to think this was going to be quantum computing… until neuromorphic computing started to emerge in a big, big way.
Neuromorphic computing alludes to a type of computing that seeks to mimic the neural structure and functioning of the human brain. While trying to mimic the brain isn’t necessarily new in computing or software, the “morph” aspect of this implies that we are capable of allowing the material sciences of a semiconductor to adjust itself. This approach to computing is fundamentally different from traditional computing paradigms, aiming to replicate the brain's extraordinary ability to process information efficiently and adaptively.

Given that this is an emerging field, there isn’t one standard way to build a neuromorphic processor yet. However, there are common principles in how they work and four distinct domains in how they differ from traditional computing:
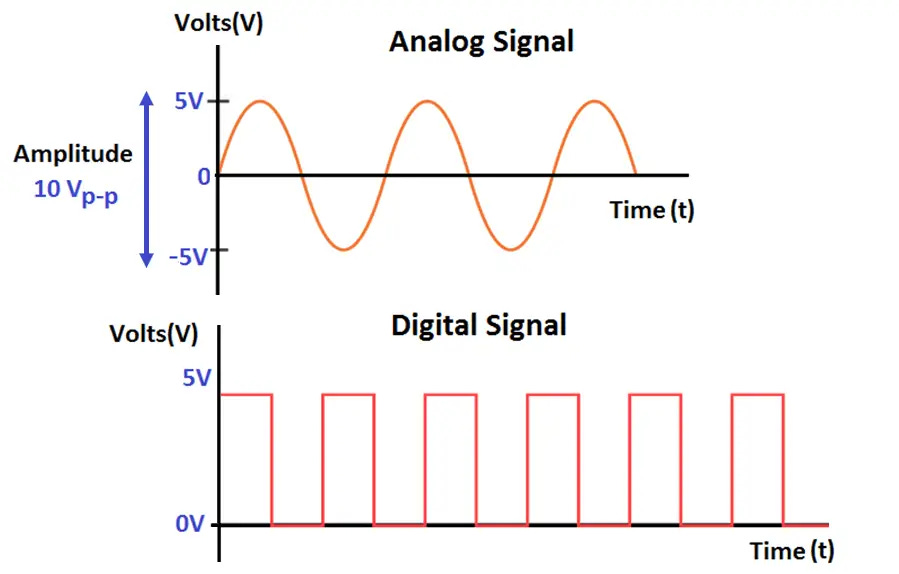
Analog Computation - While traditional computing is predominantly digital, neuromorphic systems often employ analog computation. The transistors in these systems are used to mimic the analog signal processing that occurs in biological neurons and synapses. The difference between digital vs. analog is that digital is continuous and fluid whereas analog is discrete pulses (like neurons firing in the brain). This also means that in digital, you can tightly control what gets through at what voltage in a discrete way instead of continuous fluctuations which require you to move the electricity somewhere even when you don’t need it (wasted energy).
An analogy here is like a light switch vs. a dimmer.
Memristors - Memristors are transistors whose resistance changes based on the history of a voltage applied to them, mimicking the plasticity of synapses in the brain. Memristors can retain a state of resistance even when the power is turned off, which is similar to how synapses retain the strength of their connections.
Phase-Change Materials (PCM): Neuromorphic systems can use phase-change materials to replicate synaptic functions. These materials change their physical structure—and their electrical properties—in response to electrical pulses. PCMs house “phase-change memory” - a unique property that pushes the limits of what computers can do.
Phase Change Memory (PCM) is worth talking about for a second in the context of neuromorphic computing. PCM is great for analog storage because PCM can store multiple resistance states whereas traditional digital memory can only store binary states (0 or 1), greatly increasing the amount of information that can be stored. This is much more similar to how synapses of the brain are structured. On top of that, PCM isn’t like a light switch with hardened binary states. Instead, it can gradually change in response to different electrical pulses, similar to how synapses in the brain rewire as training occurs.
One of the more interesting value-add benefits of PCM is that you can retain information for long periods of time - even without continuous power. This makes them incredibly energy efficient and is a radical departure from traditional computing. And speaking of long periods of time, PCM devices have a longer-term memory when compared to traditional memory, creating lasting durability even in the face of highly frequent use or plasticity modifications.
With regards to plasticity, my opinion is that the most unique property of PCM is that they can strengthen or weaken their synaptic connections over time. When you think about machine learning or artificial intelligence models, particularly LLMs, the training data going into them changes constantly as part of their training refinement process. To “tune” the models, we have to adjust weights to achieve benchmarks and precision/recall accuracy. From a hardware perspective, the hardware has no memory of the prior run unless it is stored somewhere in memory or disk, making it much more rigid and “one-shot-run” model tuning that humans have to have a heavy hand in.
With PCM, the physical structure can change and adapt gradually as connections strengthen and weaken over time - much more akin to a biological system. This is a huge leap forward in how we think about ML/AI because the frequency of training can be continuous without the same risk of borking models or energy costs as traditional computers.
Now, it’s not all a giant panacea in this world and we have a shit load of hurdles to get to a viable state. There are scalability issues, pure manufacturing innovation that has to occur, and interconnectivity leaps we have to make to connect billions of PCM and memristors in a way that isn’t a jumbled mess of shit. The good news here is that there is a substantial amount of capital being thrown at this problem right now as the explosion of LLM/Generative AI emerges into mainstream technology. Just like cloud computing drove significant innovations in network infrastructure, GenAI is going to drive significant innovations in new computing processors, whether that’s GPUs or neuromorphic processors.
This is what brings me back to neuromorphic vs. quantum computing. I had my money on quantum being the next leap in innovation. But I think that was false thinking for what I think is a pretty simple reason:
It’s currently much easier for us to innovate on semiconductor material sciences than it is for us to innovate on quantum physics stability.
This isn’t to say that neuromorphic computers are the only innovation happening right now. There are Tensor Processing Units (TPUs) and Intelligence Processing Units (IPUs) that already have commercial production-grade use and deployment. But, each of those architectures are steps toward the innovation of the core CPU/GPU architectures that we’ve had for years now. Important, for sure, but not a leap.
Neuromorphic computing represents a massive leap in innovation because it requires us to rethink the architecture of the chip, the material sciences we use, the kernels/software to interact with them, and the actual manufacturing process to build them. Just like CUDA made us rethink interacting with a GPU in a different, massively parallel processing way, we will need a new programming language/SDK to rethink how we process data in a system that is inspired by biology.
The leading thought here is that neural network frameworks will be the first to get ported over, given that they operate similarly to biological systems. It also coincides with where the leading innovation is happening today with companies like Tesla employing absolutely staggering amounts of specially designed CPUs in their Dojo Supercomputer to train for autonomous vehicles. We will see a lot more Dojo-like computers in the near future and, if we’re lucky, we’ll see neuromorphic processors in dense clusters leading the charge.
Now that I’ve ranted on neuromorphic computers, it’s worth calling out that I did invest in Rain AI through a syndicate investor, so I have some recency bias here. I’m not sure if they will be the winner, but I think there will be a few early winners as there usually are with industry consolidation to follow as we start to see who breaks free from the filters of innovation.
This was another longer piece to write. I hope folks find some of the history of this exciting as well as where we are headed in the future. I think I’ve said this at least 1,000 times over the last 12 months, but we are on the verge of an absolutely mind-bending curve of innovation.
To put a proxy on this, Carl Benz built the first gas-powered car in 1885. The first Ford Model A was produced in 1903. In 1908, the Ford Model T was produced and was the first cost-effective, mass-produced car. In just 23 years, we went from no one having a car to everyone having a car.
23 years ago, in the year 2000, Intel released the Pentium 4 series with a top clock speed of 1.5 GHz - single core. We barely had video games. The internet was in its infancy with it largely dominated by Geocities, stupid forums, and shit loads of porn. VR wasn’t a thing and my favorite childhood game, Runescape, wasn’t even released until 1 year later.
Today, my Samsung Galaxy S22 has an Octa-core CPU, with one core at 3.00 GHz, three cores at 2.50 GHz, and four cores at 1.80 GHz all within my pocket and connected to the entire corpus of human knowledge that is the internet. We have VR that is mindblowingly realistic. We have generative AI creating incredible works of art, audio, and video for us. They’re so real that we have a serious problem of deep fakes where it takes a sharp eye to recognize the impurities in the video (this won’t last long).
To me, what I see is our reality shattering and a new engineered emerging reality forming. I’ve long said that there really are going to only be 2 paths for humans moving forward: we will go deeper into our devices or deeper into our biological minds. Humans can’t stop tinkering with devices and biology. It’s why we call it the “singularity”. The great convergence and synthesis of biology and computers to infinity.
I hope we all take a step back in awe and recognize that 20 years from now, the world will be unrecognizable. We humans are linear thinkers. We suck at exponential thinking yet find ourselves getting launched on a curve that we’re woefully unprepared for.