
Probabilistic Knowledge Synthesis
The Probabilistic Knowledge Synthesis (PKS) proposes a novel approach for generating new knowledge by integrating open-world probabilistic databases, knowledge graphs, and language models.

Can computers create new knowledge for us? Simple question but incredibly difficult to answer. One of the key reasons this cannot happen today is that we operate off of deterministic data, models, databases, etc. In order to create new knowledge, you have to use probabilistic thinking. Otherwise known as “thinking outside of the box”. When you’re creating something truly new, you are operating out of the bounds of what’s been created already, testing frontiers that have little to no prior.
When we have a “gut” feeling, what we’re really feeling is a probabilistic weight leaning towards a potential next pattern. When you create new knowledge, this translates directly to “Instead of what the established thing is, what if we did this other thing”. We’re assigning a weight to something that is currently unknown.
Current databases don’t allow us to do this. However, there is an emerging technology that can. And that’s what sparked this whole adventure down a random rabbit hole. From the origins of quantum physics to laying down this crazy idea into text, I’ve spent some time thinking about this and I think the answer is “Yes, we can have computers create novel knowledge for us.”
Why this is so interesting to me is that I believe that you cannot have Artificial General Intelligence without first being able to have probabilistic reasoning. I believe we’ll get very high precision with deterministic reasoning as we’re already seeing this emerge with foundational large language models. But, again, this is based on known information that it is pre-trained on. For me, the “general intelligence” aspect of the phrase pins a requirement for needing to be able to operate in a probabilistic way, since intelligence by definition is “the ability to acquire and apply knowledge and skills.” Acquisition and application of knowledge is not deterministic.
Anyways, enough rambling. I recognize that this is farfetched. But hey, what’s the fun in not sharing crazy thoughts? This article is on something I’m calling Probabilistic Knowledge Synthesis - or PKS. Let’s go take a walk Beyond the Yellow Woods.
Probabilistic Knowledge Synthesis
Abstract
The Probabilistic Knowledge Synthesis (PKS) proposes a novel approach for generating new knowledge by integrating open-world probabilistic databases (OpenPDBs), knowledge graphs, and language models. The theory aims to address four key challenges in knowledge generation and reasoning:
Incomplete Knowledge Representation: Traditional databases assume missing facts have zero probability, which creates an incomplete view of the information, particularly in the context of knowledge bases.
Integrating Structured and Unstructured Data: Organizations struggle with combining information from structured databases and unstructured sources to generate relevant actions and reasoning.
Quantifying Uncertainty in Knowledge Inference: Inferring new knowledge from incomplete and uncertain data is challenging. Current solutions rely on human augmentation which is not scalable.
Continuous Knowledge Graph Expansion: Keeping knowledge graphs updated with new information and semantic reasoning is difficult at scale due to the exponential complexity of chaining and computing all possible combinations of interactions.
Of these four challenges, only two emerge as challenges that organizations are actively aware of today: 1) integrating structured and unstructured data and 2) continuous knowledge graph expansion. The other two issues (incomplete knowledge representation and quantifying uncertainty in knowledge inference) are challenges that are starting to or will emerge as we enter this new era of AI driven by large language models.
These two outstanding issues ultimately create the following problems:
Response Dilution: Broad-based LLMs will continue to be diluted as more data is added and modeled because we cannot train the frontier at sufficient resolution
Dilution leads to lack of ROI: As businesses continue to get ever-increasing, non-contextual responses from LLMs, ROI on these models will be reduced.
Lack of Perspective Reasoning: It is currently not possible to inject into a broadly trained LLM semantic reasoning from the point-of-view of an organization, creating responses that are not contextual to the organization’s viewpoint.
Exponential Knowledge Base Maintenance: As LLMs gain more adoption in organizations, the amount of text-based information explodes, creating a compounding problem of knowledge base management, pruning, and entity relationship graphing.
Public vs. Private Knowledge: Proprietary knowledge will continue to be isolated and locked up, hindering a business’s ability to strategically leverage the data they are storing
Information asymmetry cannot be unlocked: The element that generates the highest alpha in the competitive market (semantic reasoning from proprietary knowledge), which creates information asymmetry, is not incorporated into broadly trained LLMs.
The proposed theory leverages probabilistic reasoning to quantify uncertainty, knowledge graphs for structured grounding in perspective-based semantic reasoning, and language models for knowledge inference and generalization. This combination creates a potential system that can generate novel knowledge that is highly contextual, accurate, and truly novel without being considered a “hallucination”.
The knowledge generation process involves three main components:
Knowledge Representation: OpenPDBs allow assigning non-zero probabilities to unknown facts and are integrated with knowledge graphs to provide structured context and constraints.
Probabilistic Reasoning: Queries over OpenPDBs yield probability distributions over possible answers, quantifying uncertainty. Probabilistic inference enables deriving new uncertain facts from existing ones.
Knowledge Generation: A hybrid approach retrieves relevant facts from the OpenPDB and knowledge graph, generates candidate knowledge statements using a language model, evaluates and refines the statements, and integrates high-probability statements back into the knowledge base.
Probabilistic Knowledge Synthesis presents a potential approach for reliably generating new knowledge from uncertain and incomplete data by addressing key challenges in knowledge representation, data integration, uncertainty quantification, and continuous knowledge graph expansion. The aim of this post is to hopefully spark a conversation and debate about the possibilities of creating a system that is capable of novel knowledge generation and reasoning within the operational realm of uncertainty.
The Problem
Large Language Models are sophisticated pattern-matching algorithms that generate the highest plausible combination of text into responses based on the input query. The challenge is that LLMs are trained on the data they have access to. While that data is large and substantial, it doesn’t come close to the total available data in the world, particularly the data that is housed in non-public repositories.
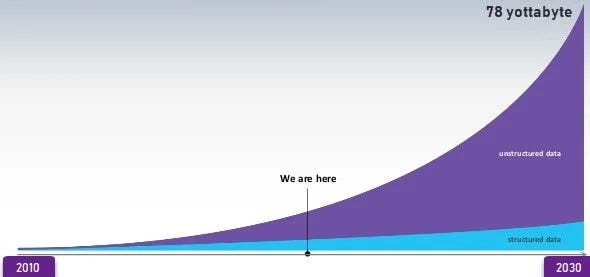
This creates a “single point of view” problem because the models are trained on the data that is available to them. Roughly 60% of private corporate data is stored in private clouds and not accessible to the public as of 2022, growing at roughly 4% per year. By 2025, approximately 72% of corporate data will be stored in private clouds. Compounding this problem is the ever-widening gap of structured vs. unstructured data. By 2030, there will be approximately 78 yottabytes of data of which >80% of that will be unstructured data. This is likely to be underestimated as the primary output of an LLM is text and the foundational models are still being leveraged largely in “early adoption” use cases.
Both public and private datasets suffer the same problem: insufficient density of topical text and sparsity of topical regions. This creates substantial “dead space” gaps within these topical regions where knowledge could potentially exist but doesn’t. Independent of each other, public and private datasets often do have the other angle of missing knowledge but cannot synthesize them for a variety of reasons (proprietary IP, PII, legal reasons, national security). Figure 1 demonstrates a visualization of an LLM-based knowledge graph of a private dataset1, showing various edges, nodes, and semantic relationships from a single point of view. However, it also demonstrates the “dead space” where there is a gap in the data that could potentially exist.

As such, organizations suffer from the problem of wanting to have these datasets integrated so that they can get more coverage on topics and map semantic reasoning into the responses, but they can’t due to the reasons described previously. The real-world implication is that we are limited in our ability to explore frontier knowledge.
Example 1: A hedge fund reaction to corporate earnings
I’m a hedge fund that has a particular macro thesis and perspective on how to make a trade, what size bet to make, and when to make that bet. Our thesis and perspective aren’t spurious: they are highly calculated based on research, IP (eg. Black-Scholes), knowledge, prior educational training, and direct experience of our interactions with the market and prior trades.
When an earnings report comes out, I need to be able to take the text of that report, analyze it, interpret it from my macro thesis perspective, and then decide what our course of trading action ought to be. This is “information asymmetry”. We take both public and non-public information, create a new angle/perspective/logical process that is novel and local to us, and then make a trading decision based on that outcome. We are creating novel “knowledge” as we react to new information coming into our view that gets synthesized with our existing data.
The key here is that the decision to make the bet is deterministic but the reasoning to get to that point is probabilistic. We don’t know for certain if it’s the correct bet or not, but we have enough confidence to place or not place the bet based on the probability distribution of “x” or “y” happening. This is a “human-in-the-loop” process that is significantly augmented with software.
This is complicated because we are dealing with gaps in data resolution, sufficiency, and clarity. Said differently, we have closed-world assumptions that need to be reconciled against open-world assumptions in a probabilistic way. As the probabilities of certain facts increase into deterministic facts (truth) when tested against open-world assumptions, they need to get back-propagated into our closed-world assumptions so that we can update our priors.
Example 2: Phenotypic and genotypic integration and analysis
I’m a large hospital network that has a heavy research focus with facilities across multiple states, working to improve personalized treatment plans for cancer patients by rapidly synthesizing phenotypic and genotypic data. Our network has access to:
Structured patient data in electronic health records (EHRs)
Clinical notes (unstructured text)
Genomic sequencing results for some patients
Published research on cancer treatments and genetic markers
Our hospital network faces several challenges in this endeavor:
Integrating structured and unstructured data: Our network struggles to combine information from structured EHR fields (e.g. lab results, medications) with unstructured clinical notes that often contain crucial observations about patient symptoms and treatment responses.
Continuous knowledge synthesis across disciplines: As new research on cancer genetics and treatments is published daily, our hospital network finds it difficult to keep clinicians and researchers updated with the latest findings given both the pace of research and the knowledge gap between disciplines.
Quantifying uncertainty in knowledge inference: When creating the best treatment plan for a patient, our clinicians have to spend a significant amount of time researching across different disciplines and then qualitatively quantifying the potential risks and uncertainty within the plan, given that we are doing with rare genetic variants or unusual symptom combinations.
Public vs. private knowledge: Our hospital network has accumulated valuable proprietary data on treatment outcomes for specific genetic profiles, but this information remains isolated from other public data sources, such as NCBI or GeneCards. We have to manually source the data from 3rd party locations and synthesize it into our perspective which is a a laborious, time-intensive task.
Why Basic RAGs fall short
One could argue that a RAG implementation is a way to cover deficiencies outlined in the above examples. After all, they are retrieving against a proprietary dataset to generate a relatively sophisticated response. However, RAGs fall short in two substantial ways that ultimately reduce the quality of results to the point where both critical systems and frontier knowledge cannot rely on them.
Lack of Entity Relationships
RAGs typically retrieve relevant passages from a text corpus based on the query and then generate an answer using a language model conditioned on the retrieved passages. However, they lack explicit modeling of entity relationships within that corpus of data.
Without modeling entity relationships, RAG systems struggle to capture important contextual information and constraints that can guide the knowledge generation process toward more reliable and coherent outputs.
Lack of Semantic Reasoning
Another limitation of basic RAGs is the lack of explicit semantic reasoning capabilities. They primarily rely on the language modeling abilities of the underlying generative model to produce plausible answers based on retrieved passages.
Without explicit semantic reasoning capabilities, RAGs generate answers that are plausible based on surface-level patterns in the retrieved passages but lack deeper understanding and consistency with the underlying knowledge structure, ultimately generating diluted responses.
Said more simply, RAGs simply regurgitate textual patterns that are found with the generative models but have no idea why those patterns surfaced. RAGs are great if you need basic generalized responses but when it comes to critical decisions or generating truly novel pieces of knowledge based on proprietary in-depth reasoning, they substantially fall short.
To solve this problem, researchers are focusing on Graph Language Models2 or GraphRAGs3 as a solution. Both of these areas of research introduce an integration of knowledge graphs at their core to capture and inject critical semantic reasoning to increase the quality of responses. This theory incorporates and expands on this area of research.
Core Components of Probabilistic Knowledge Synthesis (PKS)
The Theory of Probabilistic Knowledge Synthesis integrates open-world probabilistic databases (OpenPDBs), Graph Language Models (GLMs), and pre-trained language models to generate reliable novel knowledge. OpenPDBs allow non-zero probabilities for unknown facts, reflecting real-world scenarios with incomplete knowledge. GLMs combine structured knowledge graphs and language models for joint reasoning over graphs and text.

There are 3 main components to PKS:
Knowledge Representation
Probabilistic Reasoning
Knowledge Generation
Knowledge Representation
The Probabilistic Knowledge Synthesis represents knowledge using an open-world probabilistic database (OpenPDB) model combined with proprietary knowledge graphs and public knowledge graphs. This approach allows for effectively capturing and reasoning about uncertain and incomplete information.
Open-World Probabilistic Databases (OpenPDBs)
OpenPDBs extend traditional probabilistic databases (PDBs) by relaxing the closed-world assumption. In a traditional PDB, facts not present in the database are assumed to have a probability of zero. However, in real-world scenarios, knowledge is often incomplete and operates like an emerging property, and assigning zero probability to unknown facts may not be appropriate.4
In contrast, OpenPDBs allow for assigning non-zero probabilities to unknown facts, called open facts, from a default probability interval. Each fact (tuple) in the OpenPDB is treated as a probabilistic event with an associated likelihood. The set of facts and their probabilities define a probability distribution over all possible deterministic instances of the database.
Integration with Knowledge Graphs
To provide additional structured context and constraints on the probability space, OpenPDBs are integrated with knowledge graphs. Knowledge graphs represent entities and their relationships in a graph structure, capturing semantic information.
By combining OpenPDBs with knowledge graphs, the system can leverage the structured information from the graph to tighten the probability bounds on inferred facts. The entities and relationships from the knowledge graph act as constraints, helping to exclude spurious potentialities (worlds) and limit the probability mass of open facts within its response.
This integration allows for more informative probability bounds and improves the quality of the generated knowledge.
Probabilistic Reasoning
Probabilistic reasoning is a key component of PKS as it enables the system to reason about and infer new knowledge from uncertain and incomplete data. The probabilistic semantics of OpenPDBs provide the foundation for this reasoning process.
Querying OpenPDBs
Queries over OpenPDBs yield probability distributions over possible answers, quantifying the uncertainty in the inferred knowledge. The possible world semantics are used to interpret these queries, which involves considering all possible deterministic instances (worlds) of the probabilistic database.
To compute the probability of a query, the system sums the probabilities of all the possible worlds that satisfy the query. This process allows for capturing the uncertainty inherent in the knowledge base and propagating it to the query results.
Inferring New Knowledge
Probabilistic reasoning enables the system to infer new knowledge from the existing uncertain facts in the OpenPDB. By leveraging the probabilistic relationships between entities and facts, the system can derive new facts and assign them probabilities based on the supporting evidence.
For example, if the OpenPDB contains the facts "A is related to B with probability 0.8" and "B is related to C with probability 0.7", the system can infer the fact "A is related to C" with a probability derived from the combined evidence. This type of probabilistic inference allows for expanding the knowledge base with new, uncertain facts.
Handling Open Facts
One of the key challenges in probabilistic reasoning over OpenPDBs is handling open facts, which are unknown facts assigned probabilities from a default interval. The open-world assumption allows for more realistic modeling of incomplete knowledge but also introduces additional complexity in reasoning.
To handle open facts, the system can employ techniques such as constraining the probability space using additional knowledge representation layers or schema-level constraints. These constraints help exclude spurious possible worlds and limit the probability mass of open facts, leading to more informative probability bounds.
Efficient Query Evaluation
Evaluating queries over probabilistic databases is computationally challenging, especially for complex query classes. However, for certain classes of queries, such as safe queries, efficient evaluation algorithms exist.
For example, in tuple-independent probabilistic databases, evaluating safe queries can be done in linear time under reasonable assumptions. In OpenPDBs, this holds for a more restricted class of safe queries. Identifying and leveraging such efficiently computable query classes will be crucial for scalable probabilistic reasoning and is a critical area for further research and evaluation.
Knowledge Generation
Knowledge Generation
Knowledge Generation in the PKS involves a hybrid retrieval-augmented generation approach that combines the strengths of OpenPDBs, Graph Language Models (GLMs), and pre-trained language models. The goal is to generate novel and reliable knowledge statements by leveraging the existing knowledge base and the generative capabilities of GLMs.
Retrieval of Relevant Facts
The first step in knowledge generation is to retrieve relevant facts from the OpenPDB and the associated GLM based on a given query or context. This retrieval process aims to provide a grounding context for the subsequent generation step.
The system searches the OpenPDB to find probabilistic facts that are relevant to the query. It also traverses the GLM, which integrates the structured knowledge graph with the pre-trained language model, to identify connected entities, relationships, and textual information that can provide additional contextual information. The retrieved facts and subgraphs from the GLM form a contextual framework for generating new knowledge. This can be considered a “middle-out” query where we are simultaneously querying two systems and expecting different context responses that then get synthesized in the subsequent step.
Generating Candidate Knowledge Statements
Once the relevant context is retrieved, the GLM is employed to generate novel candidate knowledge statements. The GLM, which inherits its architecture from a Graph Transformer and its parameters from a pre-trained language model, can jointly reason over graphs and language to generate coherent and plausible statements based on the provided context.
The retrieved facts from the OpenPDB and the subgraphs from the GLM are encoded into a format that can be ingested by the GLM. This encoding process allows the GLM to incorporate both the structured information from the knowledge graph and the semantic understanding from the pre-trained language model into its generative process.
The GLM then generates a set of candidate knowledge statements based on the encoded context. These statements are novel in the sense that they are not directly present in the existing knowledge base but are inferred from the available information. Each generated statement is associated with an estimated probability, reflecting the GLM's confidence in its plausibility given the context.
Evaluation and Refinement
The generated candidate knowledge statements undergo an evaluation and refinement process to assess their reliability and consistency with the existing knowledge base. This step is crucial to ensure the quality and trustworthiness of the generated knowledge.
The system evaluates each candidate statement against the facts in the OpenPDB and the structure of the GLM. It checks for logical consistency, coherence with existing facts, and alignment with domain-specific constraints. Statements that exhibit high consistency and coherence are assigned higher probabilities, while those that conflict with existing knowledge or violate constraints are assigned lower probabilities or discarded.
The refinement process may also involve additional steps, such as cross-referencing with external sources, seeking human feedback, or applying domain-specific validation rules. These steps help to further validate and improve the quality of the generated knowledge.
Integration into the Knowledge Base
After the evaluation and refinement process, the highly probable and consistent knowledge statements are integrated back into the knowledge base. These statements are added as new facts to the OpenPDB and the GLM, with their associated probabilities reflecting the confidence in their validity.
This integration can either be done automatically once a certain probabilistic threshold has been achieved on these statements or manually through a human-in-the-loop evaluation process.
The integration of the generated knowledge expands the coverage and depth of the knowledge base over time. As more data and feedback are accumulated, the system can iteratively refine the probabilities of the generated statements and update the knowledge base accordingly.
High-Level Information Flow
While still an emerging area to discuss and explore further, the following is a general approach for how the sequence of events would emerge within a system like this to create new knowledge.
Query Formulation:
The user formulates a query either in natural language or using a structured query language, specifying the information they seek from the system.
Query Parsing and Understanding:
The system parses the user's query and interprets its intent using NLP or an out-of-the-box large language model endpoint.
Relevant Fact Retrieval:
The parsed query is used to retrieve relevant facts from the open-world probabilistic database (OpenPDB) and the associated knowledge graph.
The OpenPDB is searched for probabilistic facts that are relevant to the query, considering the uncertainty associated with each fact.
The knowledge graph is traversed to identify connected entities and relationships that provide additional context for the query.
Context Extraction:
The retrieved facts from the OpenPDB and the relevant subgraphs from the knowledge graph are extracted to form the context for knowledge generation.
This context includes both structured information from the knowledge graph and probabilistic facts from the OpenPDB.
Knowledge Generation:
The extracted context is encoded into a format that can be ingested by a language model, such as a Graph Language Model (GLM).
The GLM, which is pre-trained on a large corpus of text data and initialized with graph-aware parameters, generates novel candidate knowledge statements based on the provided context.
Each generated statement is associated with an estimated probability, reflecting the model's confidence in its plausibility given the context.
Probability Estimation and Refinement:
The generated candidate knowledge statements are evaluated against the existing facts in the OpenPDB and the structure of the knowledge graph to estimate and refine their probabilities.
The system checks for consistency, coherence, and alignment with domain-specific constraints to assign higher probabilities to statements that are more likely to be true.
The refinement process may involve additional steps, such as cross-referencing with external sources or seeking human feedback, to further validate the generated knowledge.
Result Ranking and Presentation:
The generated knowledge statements are ranked based on their estimated probabilities and relevance to the user's query.
The top-ranked statements, along with their associated probabilities, are presented to the user as the query result.
The system may also provide explanations, query lineage, or supporting evidence for the generated statements to enhance transparency and user trust.
Knowledge Base Update:
The highly probable and consistent knowledge statements generated during the query process can then be accepted and integrated back into the OpenPDB and knowledge graph.
This integration expands the knowledge base with new facts and updates the probabilities of existing facts based on the newly generated knowledge.
The updated knowledge base is then available for future queries and knowledge-generation tasks.

Throughout this process, the system leverages the open-world assumptions of the OpenPDB to handle uncertainty and incomplete knowledge, while the integration of structured knowledge from the graph and the use of GLMs enable effective reasoning and knowledge generation. The iterative refinement and expansion of the knowledge base allow the system to continuously improve its performance and adapt to new information over time. Simultaneously, it generates a form of information entanglement between two systems that both have incomplete information, allowing queried knowledge to converge into “fact” (ie. single perspective) that ranks high on the probability distribution of being “truth” (ie. multiple perspectives).
A Physics Parallel: PKS and Quantum Physics
The original inception of this theory comes from the wave function collapse principles found in quantum physics.
In quantum physics, a quantum system is described by a wave function that encodes the probabilities of the system being in various possible states. The wave function evolves deterministically according to the Schrödinger equation. However, when a measurement is performed on the system, the wave function is said to "collapse" into a definite state, with the probability of each possible outcome given by the square of the absolute value of the wave function.
Similarly, a probabilistic knowledge base like an OpenPDB can be thought of as a "wave function" over possible knowledge states. Each possible fact in the knowledge base is associated with a probability, and the overall state of the knowledge base is a superposition of all these possible facts weighted by their probabilities.
When a query is made against the probabilistic knowledge base, it can be seen as analogous to performing a "measurement" on the system. The query "collapses" the probabilistic knowledge state into a definite answer, with the probabilities of each possible answer given by the marginal probabilities of the relevant facts in the knowledge base.
Just as the quantum wave function evolves deterministically between measurements according to the Schrödinger equation, the probabilistic knowledge base can evolve as new facts are added, probabilities are updated based on evidence, and knowledge is inferred through probabilistic reasoning. However, at the moment a definite query is made, the knowledge base "collapses" into a specific answer state.
Extending the analogy further, the integration of an OpenPDB with a knowledge graph could be seen as preparing an "entangled" quantum state. The correlations and constraints encoded in the knowledge graph "entangle" the probabilities and their bounds of related facts, leading to more informed and constrained probability distributions when a query "measurement" is made.

In this view, the PKS theory proposed here is akin to a "quantum theory of knowledge" - modeling the uncertain and evolving state of a knowledge base as a probability distribution, and the extraction of definite answers through queries as a form of wave function collapse. The integration of multiple knowledge representation and reasoning approaches creates "entangled" knowledge states that can generate novel insights through constructive interference of probabilities.
Future Discussions
PKS is a novel theory that stems from principles that we see in quantum mechanics. However, the main elements of this theory are built on the foundation of research that is still emerging - specifically OpenPDBs. There is sufficient evidence at this point that Graph Language Models, GraphRAGs, and other similar technologies will ultimately emerge as providing substantive value to an organization.
One key area of further discussion is the integration of AI Agents as a layer on top of PKS. In considering PKS, there is a question of how far Agents could extend if they were instead scoped to a specific ontology within a knowledge graph. This would significantly constrain the probabilistic query range required to realize PKS which is the trade-off to consider here. In this theory, computationally handling these queries and making them cost-effective proposes a significant hurdle given the sheer magnitude of data required to query and compute through.
However, if Agents were constrained to specific ontologies or topical domains, the scope and bounds of the query would be significantly reduced, enabling compute and cost to go much further.
This is already an active area of research notably at Microsoft and MIT. A recently released paper titled “SciAgents: Automating Scientific Discovery Through Multi-Agent Intelligent Graph Reasoning”5 went down the route of exploring knowledge graphs and agents integrated with generative models. Their paper explores the generation of knowledge based on known facts within the LLMs and knowledge graphs but cannot handle unknown potential facts. This is where probabilistic databases start to play a role.
Outside of Agents, there is a deep need to continue to explore OpenPDBs. This domain for research has only started to emerge in the last 5-7 years with clearer examples, use cases, and testing data. That said, much of the research is still academic and theoretical, lacking the substance for an organization to truly explore its incorporation into their technology stack.
Lastly, there is the recognition that this theory is out there. A lot has to go right for it to work from an architecture and technology perspective. Even if both of those emerged with more mature technology, there is still the open question of applicable use cases with commensurate ROI for an organization. Standing up a system like this would be no trivial technical nor cost-effective effort, requiring clarity on the use case and metric-verified ROI.
With that all being said, I believe the theory is worth exploring. We are at the junction where we need to make significant bets on systems that can generate novel knowledge for us so that we can guide these systems towards what areas of research we need novel knowledge in. I view this both as paramount to the long-term success of humans as well as a critical precursor in our quest to create Artificial General Intelligence (AGI). If we want to create a world of abundance, we must conquer and master the foundations that make this reality ours. To become a ubiquitous civilization amongst the stars, we must change our ability to create novel knowledge from a linear sequence constrained by human labor to an exponential sequence made abundant by the augmentation of systems that can generate novel knowledge, guided by humans.
Resources & References:
https://aclanthology.org/2024.acl-long.245.pdf
https://www.sciencedirect.com/science/article/abs/pii/S0004370221000254
https://arxiv.org/pdf/1807.00607
https://ojs.aaai.org/index.php/AAAI/article/view/10680/10539
https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/
https://arxiv.org/pdf/1807.00607
https://arxiv.org/pdf/2409.05556
Very cool ideas Ryan. I had too much to say for a comment so I wrote a blog post of my own in response. tldr is that I believe LLMs alone are enough to achieve what you described, without the need for PDBs and graphs. Here's my blog post: https://skillenai.com/2024/09/26/can-llms-synthesize-new-knowledge/